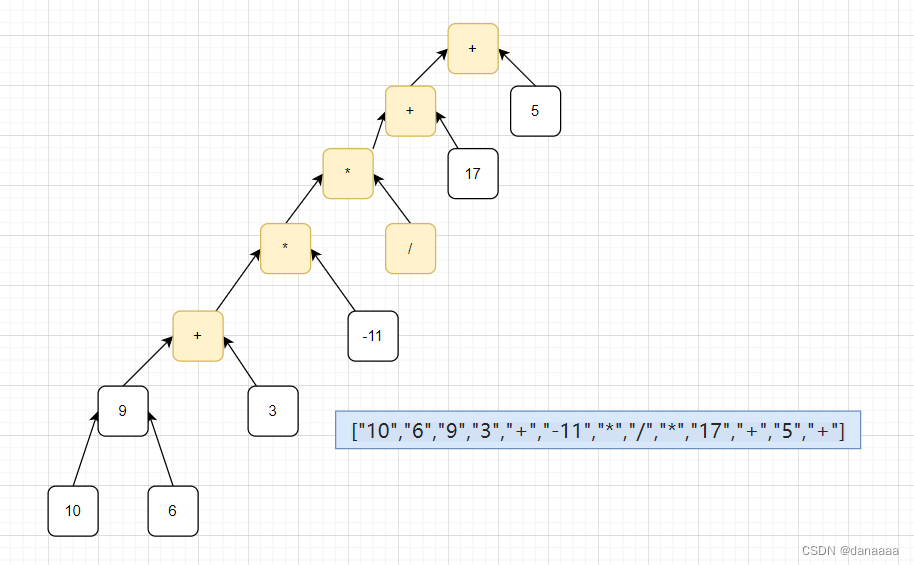
目录
- 一、算法介绍
- 1、算法
- 1)基于编辑距离
- 2)基于标记
- 3)基于序列
- 4)基于压缩
- 5)基于发音
- 6)简单算法
- 2、安装
- 二、代码demo
- 1、Hamming 距离
- 2、Levenshtein 距离
- 3、Damerau-Levenshtein距离
- 4、Jaro 相似度
- 5、Jaro-Winkler相似度
- 6、Smith–Waterman相似度
- 7、Jaccard 相似度
- 8、Sørensen-Dice 相似度
- 9、Tversky 相似度
- 10、Overlap coefficient相似度
- 11、Cosine similarity相似度
- 12、N-gram相似度
- 13、最长公共子字符串/子序列相似度
- 14、Ratcliff-Obershelp相似度
- 三、效果分析
- 1、中文文本字符串
- 1)效果最好排序
- 2)速度最快排序
- 3)综合排序
- 2、其他
- 1)基于压缩的应用场景
- 2)基于发音的应用场景
- 3)简单算法的应用场景
一、算法介绍
1、算法
1)基于编辑距离
| 算法 | 类 | 函数 |
|---|---|---|
| Hamming | Hamming | hamming |
| MLIPNS | Mlipns | mlipns |
| Levenshtein | Levenshtein | levenshtein |
| Damerau-Levenshtein | DamerauLevenshtein | damerau_levenshtein |
| Jaro-Winkler | JaroWinkler | jaro_winkler, jaro |
| Strcmp95 | StrCmp95 | strcmp95 |
| Needleman-Wunsch | NeedlemanWunsch | needleman_wunsch |
| Gotoh | Gotoh | gotoh |
| Smith-Waterman | SmithWaterman | smith_waterman |
2)基于标记
| 算法 | 类 | 函数 |
|---|---|---|
| Jaccard index | Jaccard | jaccard |
| Sørensen–Dice coefficient | Sorensen | sorensen, sorensen_dice, dice |
| Tversky index | Tversky | tversky |
| Overlap coefficient | Overlap | overlap |
| Tanimoto distance | Tanimoto | tanimoto |
| Cosine similarity | Cosine | cosine |
| Monge-Elkan | MongeElkan | monge_elkan |
| Bag distance | Bag | bag |
3)基于序列
| 算法 | 类 | 函数 |
|---|---|---|
| 最长公共子序列相似度 | LCSSeq | lcsseq |
| 最长公共子串相似度 | LCSStr | lcsstr |
| Ratcliff-Obershelp 相似度 | RatcliffObershelp | ratcliff_obershelp |
4)基于压缩
使用不同压缩算法的归一化压缩距离。
经典压缩算法:
| 算法 | 类 | 函数 |
|---|---|---|
| 算术编码 | ArithNCD | arith_ncd |
| RLE | RLENCD | rle_ncd |
| BWT RLE | BWTRLENCD | bwtrle_ncd |
常见压缩算法:
| 算法 | 类 | 函数 |
|---|---|---|
| 平方根 | SqrtNCD | sqrt_ncd |
| 熵 | EntropyNCD | entropy_ncd |
正在开发的算法,将两个字符串比较为比特数组:
| 算法 | 类 | 函数 |
|---|---|---|
| BZ2 | BZ2NCD | bz2_ncd |
| LZMA | LZMANCD | lzma_ncd |
| ZLib | ZLIBNCD | zlib_ncd |
5)基于发音
| 算法 | 类 | 函数 |
|---|---|---|
| MRA | MRA | mra |
| Editex | Editex | editex |
6)简单算法
| 算法 | 类 | 函数 |
|---|---|---|
| 前缀相似度 | Prefix | prefix |
| 后缀相似度 | Postfix | postfix |
| 长度距离 | Length | length |
| 身份相似度 | Identity | identity |
| 矩阵相似度 | Matrix | matrix |
2、安装
仅纯Python实现:
pip install textdistance
带有额外库以实现最大速度:
pip install "textdistance[extras]"
包含所有库(用于基准测试和测试):
pip install "textdistance[benchmark]"
带有特定算法的额外库:
pip install "textdistance[Hamming]"
提供额外库的算法有:DamerauLevenshtein、Hamming、Jaro、JaroWinkler、Levenshtein。
二、代码demo
1、Hamming 距离
>> import textdistance as td
>> td.hamming('book', 'look')
1
>> td.hamming.normalized_similarity('book', 'look')
0.75
>> td.hamming('bellow', 'below')
3
>> td.hamming.normalized_similarity('Below', 'Bellow')
0.5
在第一个示例中,有一个不同的字符。这使得距离等于1,归一化相似度等于(4-1)/4 = 75%。在第二个示例中,比较“bellow”和“below”,前三个字母相同,但接下来的三个字母不同。因此,距离是3,归一化相似度是(6-3)/6 = 50%。
2、Levenshtein 距离
>> td.levenshtein('book', 'look')
1
>> td.levenshtein.normalized_similarity('book', 'look')
0.75
>> td.levenshtein('bellow', 'below')
1
>> td.levenshtein.normalized_similarity('Below', 'Bellow')
0.84
在第一个示例中,可以通过替换一个字母来得到另一个单词,因此归一化相似度是(4-1)/4 = 75%。在第二个示例中,有一个插入操作,因此距离是1,归一化相似度是(6-1)/6 = 84%。
3、Damerau-Levenshtein距离
>> td.levenshtein('act', 'cat')
2
>> td.levenshtein.normalized_similarity('act', 'cat')
0.34
>> td.damerau_levenshtein('act', 'cat')
1
>> td.damerau_levenshtein.normalized_similarity('act', 'cat')
0.67
Damerau-Levenshtein距离是Levenshtein 距离的一个变种,应用广泛,如拼写检查和序列分析
4、Jaro 相似度
>> td.jaro('bellow', 'below')
0.94
>> td.jaro('simple', 'plesim')
0
>> td.jaro('jaro', 'ajro')
0.92
在第一个示例中,有5个匹配字符和一个插入(这不是置换操作),因此Jaro 相似度为1/3*(5/6+5/5+6/6)。在第二个示例中,有0个匹配字符,因为共同字符不在max(|s1|, |s2|)/2-1的范围内。这就是为什么相似度为0的原因。在最后一个示例中,有4个匹配字符和第一和第二字母之间的1个置换操作,因此相似度为1/3 * (4/4+4/4+3/4) = 0.91。
5、Jaro-Winkler相似度
>> td.jaro("simple", "since")
0.7
>> t.jaro_winkler("simple", "since")
0.76
由于两个字符串有两个共同的前缀字母。Jaro-Winkler相似度大于Jaro相似度:0.7 + 0.12(1–0.7) = 0.7 + 0.06 = 0.76。
6、Smith–Waterman相似度
>> td.smith_waterman("GATTACA", "GCATGCU")
3
>> td.smith_waterman("GATTACA", "GCATGCU")
0.43
Smith–Waterman算法在生物信息学中特别有用,用于识别生物序列中的相似区域或基序
7、Jaccard 相似度
>> td.jaccard('jaccard similarity'.split(), "similarity jaccard".split())
1
>> td.jaccard('jaccard similarity'.split(), "similarity jaccard jaccard".split())
0.66
类似交并比(Intersection of Union,IoU),对比时并不考虑字符串单词的顺序
8、Sørensen-Dice 相似度
>> td.sorencen('jaccard similarity'.split(), "similarity jaccard".split())
1
>> td.sorencen('jaccard similarity'.split(), "similarity jaccard jaccard".split())
0.8
与前者相比,不考虑重复元素
9、Tversky 相似度
>> td.sorencen('tversky similarity'.split(), "similarity tversky tversky".split())
0.8
>> tversky = td.Tversky(ks=(0.5, 0.5))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.8
>> td.jaccard('tversky similarity'.split(), "similarity tversky tversky".split())
0.67
>> tversky = td.Tversky(ks=(1, 1))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.67
>> tversky = td.Tversky(ks=(0.2, 0.8))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.74
10、Overlap coefficient相似度
>> td.overlap('overlap similarity'.split(), "similarity overlap overlap".split())
1.0
计算集合交集大小与较小集合大小的比例
11、Cosine similarity相似度
>> td.cosine('cosine'.split(), "similarity".split())
0
>> td.cosine('cosine sim'.split(), "cosine sim sim".split())
0.81
12、N-gram相似度
N-gram 相似度是一种基于字符串中连续N个字符的相似度度量方法。它通过将字符串拆分为N-gram(N个连续字符的子串),然后比较这些N-gram的集合来计算两个字符串之间的相似度。下面是用 Python 实现 N-gram 相似度的代码示例:
def ngrams(string, n):
"""将字符串拆分为N-gram"""
return [string[i:i+n] for i in range(len(string)-n+1)]
def ngram_similarity(str1, str2, n):
"""计算两个字符串的N-gram相似度"""
ngrams1 = set(ngrams(str1, n))
ngrams2 = set(ngrams(str2, n))
intersection = ngrams1.intersection(ngrams2)
union = ngrams1.union(ngrams2)
return len(intersection) / len(union) if union else 0.0
# 示例
str1 = "hello"
str2 = "hallo"
n = 2
similarity = ngram_similarity(str1, str2, n)
print(f"{n}-gram 相似度: {similarity:.2f}")
# 2-gram 相似度: 0.33
13、最长公共子字符串/子序列相似度
>> s1, s2 = "RO PATTERN MATCHING", "RO PRACTICE"
>> td.lcsstr(s1, s2), td.lcsseq(s2, s1), td.lcsseq(s2, s1)
('RO P', 'RO PRATC', 'RO PRACI')
>> td.lcsstr.normalized_similarity(s1, s2), td.lcsseq.normalized_similarity(s1, s2)
(0.21, 0.42)
最长公共子字符串专注于找出两个字符串之间的最长公共子字符串,它通过识别两个字符串共享的最长连续字符序列来衡量字符串之间的相似度
子序列不要求在原始序列中占据连续位置。因此,最长公共子序列总是大于最长公共子字符串
14、Ratcliff-Obershelp相似度
>> s1, s2 = "RO PATTERN MATCHING", "RO PRACTICE"
>> td.ratcliff_obershelp(s1, s2), td.ratcliff_obershelp(s2, s1), len(s1), len(s2)
(0.46, 0.53, 19, 11)
三、效果分析
1、中文文本字符串
在对中文文本字符串进行相似度比较时,效果和速度各有不同的算法可供选择。以下是根据效果最好和速度最快分别排序的算法:
1)效果最好排序
- Levenshtein:计算编辑距离,考虑到中文字符的插入、删除和替换,效果较好。
- Damerau-Levenshtein:比Levenshtein更进一步,考虑到字符的交换,能更准确地反映一些错别字的相似性。
- Jaro-Winkler:考虑字符的匹配和位移,对拼音和形近字有较好的识别效果。
- Needleman-Wunsch:常用于序列比对,适合处理长文本,但速度较慢。
- Smith-Waterman:和Needleman-Wunsch类似,但更精细,适合局部相似性比对。
- Cosine similarity:基于向量空间模型,适合处理词语或短句相似度,但需要预处理成向量表示。
- Jaccard index:基于集合的相似度计算,适合分词后的文本比较。
2)速度最快排序
- Hamming:适合固定长度的字符串比较,速度极快,但只能比较长度相同的字符串。
- Jaccard index:基于集合操作,速度较快,尤其是在分词后的文本上。
- Cosine similarity:向量化处理后计算余弦相似度,速度较快,但依赖预处理。
- Jaro-Winkler:速度相对较快,适合短文本比较。
- Levenshtein:虽然是动态规划算法,但优化后速度也较快,适合中短文本比较。
- Damerau-Levenshtein:考虑交换操作,稍慢于Levenshtein,但仍然较快。
- Smith-Waterman:局部比对,速度较慢,适合较短文本。
- Needleman-Wunsch:全局比对,速度慢,适合处理长文本。
3)综合排序
结合效果和速度,以下是综合排序:
- Levenshtein:综合效果和速度,适合大多数情况。
- Damerau-Levenshtein:效果好于Levenshtein,速度稍慢,但仍然适用。
- Jaro-Winkler:适合拼音和形近字,速度较快。
- Cosine similarity:需要预处理,但在向量化后速度较快,效果也不错。
- Jaccard index:适合分词后的文本比较,速度快。
- Needleman-Wunsch:适合长文本,效果好但速度慢。
- Smith-Waterman:适合局部相似性比较,效果好但速度最慢。
选择具体算法时,可以根据文本的长度、预处理的复杂度以及对效果的要求来综合考虑。
英文文本也适用
2、其他
1)基于压缩的应用场景
基于压缩的算法主要用于处理和比较大规模或复杂的数据集,因为它们能够有效地压缩和分析数据。这些算法常用于以下场景:
- 大数据分析:在需要处理和比较大量文本数据的场景中,如日志文件、网络爬虫数据等。
- 数据压缩和传输:在需要高效压缩和传输数据的应用中,这些算法可以用于优化数据存储和传输效率。
- 文本和字符串匹配:用于需要在大文本库中查找相似文本或字符串的场景。
2)基于发音的应用场景
基于发音的算法主要用于处理语音和文本的相似性计算,这在以下场景中尤为有用:
- 语音识别和处理:在语音识别系统中,用于比较和识别发音相似的词汇。
- 拼写纠正:在文本输入系统中,根据发音相似性来纠正拼写错误。
- 名称匹配:用于比较和匹配发音相似的人名、地名等,如客户关系管理系统中匹配相似的客户名字。
3)简单算法的应用场景
简单算法通常用于需要快速、直接比较的场景,这些场景不需要复杂的计算或大量数据处理:
- 前缀和后缀匹配:用于文件名或路径的匹配和分类,如查找特定前缀或后缀的文件。
- 长度比较:用于需要比较字符串长度的场景,如数据验证和清理。
- 身份相似度:用于简单的字符串相等性比较,如用户输入的验证码验证。
- 矩阵相似度:用于矩阵数据的比较,如图像处理中的像素矩阵比较。